本文共 5261 字,大约阅读时间需要 17 分钟。
 ZAB协议:Zookeeper Atomic Broadcast,ZK原子广播协议; ZAB协议中存在三种状态: (1) Looking, (2) Following, (3) Leading 整体工作过程四个阶段: 选举:election 发现:discovery 同步:sync 广播:Broadcast
ZAB协议:Zookeeper Atomic Broadcast,ZK原子广播协议; ZAB协议中存在三种状态: (1) Looking, (2) Following, (3) Leading 整体工作过程四个阶段: 选举:election 发现:discovery 同步:sync 广播:Broadcast
 zk是java研发的,需要准备好jdk,把官方编译好的zk下载下来 伪分布式模式(在一台主机上启动三个zk进程,分别使用不同的端口号,) 分布式模式,至少有三个节点
zk是java研发的,需要准备好jdk,把官方编译好的zk下载下来 伪分布式模式(在一台主机上启动三个zk进程,分别使用不同的端口号,) 分布式模式,至少有三个节点  先运行单机模式简单看一下
先运行单机模式简单看一下 

 http://zookeeper.apache.org
http://zookeeper.apache.org 展开到usr/local目录

 初始同步阶段,要经过多少个take时长。10个take时长,一个是两秒,10个就是20秒
初始同步阶段,要经过多少个take时长。10个take时长,一个是两秒,10个就是20秒  发个请求最多要经过多少个take周期。5个,10秒
发个请求最多要经过多少个take周期。5个,10秒  数据目录,zk数据都是在内存中的,一挂数据就没有了,也采用了redis的方式,把内存中的数据给快照至指定的存储位置,放在tmp不是很妥当的做法
数据目录,zk数据都是在内存中的,一挂数据就没有了,也采用了redis的方式,把内存中的数据给快照至指定的存储位置,放在tmp不是很妥当的做法  客户端连接哪个端口来提供服务,监听的端口
客户端连接哪个端口来提供服务,监听的端口  最大并发连接数,zk是分布式集群,正常情况下,配置zk的各节点,
最大并发连接数,zk是分布式集群,正常情况下,配置zk的各节点, 


安装: 部署方式:单机模式、伪分布式模式、分布式模式 http://zookeeper.apache.org
zoo.cfg配置参数: tickTime=2000 dataDir=/data/zookeeper ClientPort=2181 initLimit=5 syncLimit=2
指定主机的语法格式: server.ID=IP:port:port ID:各主机的数字标识,一般从1开始 IP:各主机的IP 一般port使用2888,3888,用没有占用的端口就行,主要用于各节点的,之间做集群角色,通信时使用,
只有一个主机写下面 启动服务,再bin目录下,2181
启动服务,再bin目录下,2181 主要用 的是2181端口
主要用 的是2181端口 与zk通信,客户端程序zkcl
 建议以后使用不用root用户,创建数据目录
建议以后使用不用root用户,创建数据目录 退出,然后重启zk服务
退出,然后重启zk服务 使用客户端工具
使用客户端工具 ?号获取帮助
?号获取帮助 连接服务器ip端口
连接服务器ip端口 如果使用外网地址可以使用
如果使用外网地址可以使用 告诉你sasl认证失败
告诉你sasl认证失败 外网地址可能连接有认证的过程 创建指定的路径,并赋予数据,定义ACL -s -e分别表示顺序节点,还是临时节点(持久节点和临时节点) 顺序节点可以理解为两个节点的某一类型 顺序节点,创建时被分配一个唯一并且独占的递增性整数作为节点号,此号码会被附加在节点路径之后,
外网地址可能连接有认证的过程 创建指定的路径,并赋予数据,定义ACL -s -e分别表示顺序节点,还是临时节点(持久节点和临时节点) 顺序节点可以理解为两个节点的某一类型 顺序节点,创建时被分配一个唯一并且独占的递增性整数作为节点号,此号码会被附加在节点路径之后,  现在跟下没有任何东西,在跟下创建test,data给数据,acl可以给一个访问控制列表,默认为不施加任何控制,所有人都可以访问,节点类型不指明,为持久节点,“”test“”数据 在跟之下有一个test zookeeper是自己默认的
现在跟下没有任何东西,在跟下创建test,data给数据,acl可以给一个访问控制列表,默认为不施加任何控制,所有人都可以访问,节点类型不指明,为持久节点,“”test“”数据 在跟之下有一个test zookeeper是自己默认的  列出指定路径下的所有1级节点,不递归并显示节点的属性信息
列出指定路径下的所有1级节点,不递归并显示节点的属性信息  显示test的自己的状态包括test下的路径,并且test的相关属性信息也显示在这了,这些属性可以有state获取
显示test的自己的状态包括test下的路径,并且test的相关属性信息也显示在这了,这些属性可以有state获取 ls2类似stat和ls整合起来 获取指定数据的内容,显示test节点下的内容
ls2类似stat和ls整合起来 获取指定数据的内容,显示test节点下的内容 
 更新数据用set
更新数据用set 
 delete删除节点
delete删除节点 
 test下如果有子路径还需要递归删除 rmr
test下如果有子路径还需要递归删除 rmr  在test下创建子路径node1,node2,ls显示test下有1,2
在test下创建子路径node1,node2,ls显示test下有1,2 rmr递归删除
acl访问控制列表的权限无非就是create,delete,read,write,admin zk的节点两种,持久和临时 持久节点只能使用delete和rmr删除 临时节点再客户端链接断开后,会自动删除 当master意外断开zk,zk为了选举新的leader来,就应该使用临时节点,临时节点在对应的会话创建以后,就会删除,所以临时节点不应该有子节点 -e 临时节点
 再次链接test就没有了
再次链接test就没有了 创建持久的,退出,重新连入
创建持久的,退出,重新连入 持久节点仅能通过delete或者rmr删除
持久节点仅能通过delete或者rmr删除 顺序节点只是附加的属性,在创建时被分配一个唯一且独占的递增性数字当做节点号,此号码附加在节点后,随时供其唯一来标识自己 zk可以生成4种节点 1.持久节点 2.持久顺序节点 3.临时节点 4.临时顺序节点
顺序节点只是附加的属性,在创建时被分配一个唯一且独占的递增性数字当做节点号,此号码附加在节点后,随时供其唯一来标识自己 zk可以生成4种节点 1.持久节点 2.持久顺序节点 3.临时节点 4.临时顺序节点 创建数据后可以用stat来获取节点的相关数据
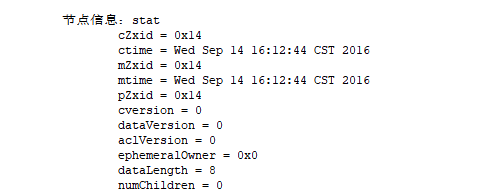
事务id是更新的不断增长的,对zk而言是对你的会话相关的,跟当前事务本身相关,在一段时间内都属于同一个事务
创建时间 最近更新该节点的事务id
最近更新该节点的事务id 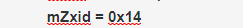
 p自己做为parent父节点,就是用来标识各子节点的状态,表示该节点的子节点列表最近一次被修改的事务id
p自己做为parent父节点,就是用来标识各子节点的状态,表示该节点的子节点列表最近一次被修改的事务id  子节点版本号
子节点版本号  acl的版本号
acl的版本号  数据版本号
数据版本号 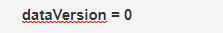
创建该临时节点的id,如果不是临时节点就是0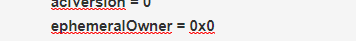
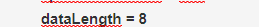 子节点的个数
子节点的个数  zookeeper中的版本号主要标识相关信息的修改次数的,因此没被修改过都是0,被改过就是几 zookeeper使用乐观并发访问控制机制,实现了写入校验机制,与悲观的比,特事务彼此间一定会出现干扰 乐观的机制,在对于干扰的隔离上,要宽松的多。事务要改就改,不会去请求锁 悲观,每一次的修改操作前,都必须先请求锁,然后进行修改 zookeeper是乐观的,是假设各事务之间彼此间没有任何干扰,因此,修改直接改,不要请求锁机制, 当前事务读到数据以后,还需要监控,是否有其他事务试图正在修改这个数据,如果正在更新,还需要回滚,意思当前事务是没法成功的,重新读,因为别人已经更新过了,所以这样可能有大量的回滚操作,在干扰过多的时,节点只会修改一个节点上的数据,并发访问同一个数据是比较小的 版本并发访问控制是对应,共享数据集合是非常基本的概念,有两种模型 悲观乐观 mysql是悲观 可以了解悲观并发访问控制机制,每一次做修改操作前,都要先请求锁 乐观是假设没有干扰的,就地直接修改,为了避免真正产生干扰,会在读取完数据以后,会检查数据是否真正被修改了,如果改了需要回滚,
zookeeper中的版本号主要标识相关信息的修改次数的,因此没被修改过都是0,被改过就是几 zookeeper使用乐观并发访问控制机制,实现了写入校验机制,与悲观的比,特事务彼此间一定会出现干扰 乐观的机制,在对于干扰的隔离上,要宽松的多。事务要改就改,不会去请求锁 悲观,每一次的修改操作前,都必须先请求锁,然后进行修改 zookeeper是乐观的,是假设各事务之间彼此间没有任何干扰,因此,修改直接改,不要请求锁机制, 当前事务读到数据以后,还需要监控,是否有其他事务试图正在修改这个数据,如果正在更新,还需要回滚,意思当前事务是没法成功的,重新读,因为别人已经更新过了,所以这样可能有大量的回滚操作,在干扰过多的时,节点只会修改一个节点上的数据,并发访问同一个数据是比较小的 版本并发访问控制是对应,共享数据集合是非常基本的概念,有两种模型 悲观乐观 mysql是悲观 可以了解悲观并发访问控制机制,每一次做修改操作前,都要先请求锁 乐观是假设没有干扰的,就地直接修改,为了避免真正产生干扰,会在读取完数据以后,会检查数据是否真正被修改了,如果改了需要回滚, watcher机制,监视器,zk是基于网络通信的远程服务,如果clinet特别关注节点的信息,就可以在节点上注册一个监听器 ,一旦发生改变,zk将会将其改变的事件通知给注册监听器的客户端,但是监听器是一次性的 一旦注册,zk发现事件改变通知了,下次再使用就需要重新注册 如果需要重新建立watcher,通常要用到zookeeper的API调用来进行
 每一个客户端连接zk以后,都会有一个会话,对应的会话会始终被记录在zk中,临时节点跟会话还是有很大关系的,一旦连接超时或断开了,所有的临时节点都会被清空 的 对应的 当客户端去建立连接时,这个状态称为connecting,连接,一旦连接建立以后就是connected,已连接,如果不使用或者超时断开了,将显示为not connected,如果自己断开,没有任何连接,显示为closed
每一个客户端连接zk以后,都会有一个会话,对应的会话会始终被记录在zk中,临时节点跟会话还是有很大关系的,一旦连接超时或断开了,所有的临时节点都会被清空 的 对应的 当客户端去建立连接时,这个状态称为connecting,连接,一旦连接建立以后就是connected,已连接,如果不使用或者超时断开了,将显示为not connected,如果自己断开,没有任何连接,显示为closed zookeeper有很多4字命令的命令,简单来讲就是对数据进行简单修改更新等操作 4 个字符所构成的命令,如ryok
 ruok恢复imok stat显示zookeeper版本,构建时间,clients相关的节点信息 latency延迟最小时间,最大时间,平均值
ruok恢复imok stat显示zookeeper版本,构建时间,clients相关的节点信息 latency延迟最小时间,最大时间,平均值 显示srvr信息与stat类似,stat可以显示连接信息 srvr只显示服务端信息 conf显示启动时用的配置参数
显示srvr信息与stat类似,stat可以显示连接信息 srvr只显示服务端信息 conf显示启动时用的配置参数 当前服务器的ID号
当前服务器的ID号  只是telnet断开而已
只是telnet断开而已  cons显示有几个客户端
cons显示有几个客户端 4字命令主要实现zookeeper监控的
4字命令主要实现zookeeper监控的 监控zk的四字命令: ruok, stat, srvr, conf, cons, wchs(有哪些监听器), envi(显示zk运行 的java jdk环境配置信息) …
监控zk的四字命令: ruok, stat, srvr, conf, cons, wchs(有哪些监听器), envi(显示zk运行 的java jdk环境配置信息) … zk的接口命令
zk的接口命令  zkCli命令: create, ls, ls2, stat, delete, rmr, get, set, …
zkCli命令: create, ls, ls2, stat, delete, rmr, get, set, … zoo.cfg配置文件的参数: 基本配置参数: clientPort=2181 客户端端口 dataDir=/data/zookeeper snapshoot放的位置。默认放的是数据目录 dataLogDir:事务日志文件路径;aof顺序方式写入 tickTime:
zoo.cfg配置文件的参数: 基本配置参数: clientPort=2181 客户端端口 dataDir=/data/zookeeper snapshoot放的位置。默认放的是数据目录 dataLogDir:事务日志文件路径;aof顺序方式写入 tickTime:  存储配置: preAllocSize:为事务日志预先分配的磁盘空间量;默认65535KB 65M;(每次快照都会重启事务日志,如果大小不够,会提交snapshoot,可以考虑增大这个值) snapCount:每多少次事务后执行一次快照操作;每事务的平均大小在100字节; (快照读取数据,事务的重放速度,决定了启动速度 事务日志过大,重放速度慢,加载快照的速度比较快,建议不要把事务日志文件设置过大) autopurget(自动修剪清零).snapRetainCount:指明自动删除留下来多少 autopurge.purgeInterval:purge操作的时间间隔,0表示不启动; fsync(把数据从内存同步到磁盘上).warningthresholdms:zk进行事务日志fsync操作时消耗的时长报警阈值;(如果这次操作执行时间过长,去提醒用户,如果fsync时间过长,要么是在内存中同步时间太长,要么是磁盘压力太大,导致写出不成功) 事务日志也是先保存在内存中 weight.X=N:判断quorum时(法定投票)投票权限,默认1;
存储配置: preAllocSize:为事务日志预先分配的磁盘空间量;默认65535KB 65M;(每次快照都会重启事务日志,如果大小不够,会提交snapshoot,可以考虑增大这个值) snapCount:每多少次事务后执行一次快照操作;每事务的平均大小在100字节; (快照读取数据,事务的重放速度,决定了启动速度 事务日志过大,重放速度慢,加载快照的速度比较快,建议不要把事务日志文件设置过大) autopurget(自动修剪清零).snapRetainCount:指明自动删除留下来多少 autopurge.purgeInterval:purge操作的时间间隔,0表示不启动; fsync(把数据从内存同步到磁盘上).warningthresholdms:zk进行事务日志fsync操作时消耗的时长报警阈值;(如果这次操作执行时间过长,去提醒用户,如果fsync时间过长,要么是在内存中同步时间太长,要么是磁盘压力太大,导致写出不成功) 事务日志也是先保存在内存中 weight.X=N:判断quorum时(法定投票)投票权限,默认1; 网络配置: initLimit:配置Follower连入Leader并完成数据同步的时长(真长市场10*ticktime的时间) maxClientCnxns:每客户端IP的最大并发连接数;客户端60(5 台服务器,zk每台服务器最大并发1000,总共5000/60) clientPortAddress:zk监听IP地址;(不指明就是本机的所有地址) minSessionTimeout:会话最短超时时间,默认tiki值的两倍 maxSessionTimeout:最大会话超时时长
集群配置: initLimit:Follower连入Leader并完成数据同步的时长; syncLimit:leader和follower心跳检测的最大延迟; leaderServes:默认zk的leader接收读写请求,额外还要负责协调各Follower发来的事务等; 因此,为使得leader集中处理zk集群内部信息,建议不让leader直接提供服务; cnxTimeout:Leader选举期间,各服务器创建TCP连接的超时时长; ellectionAlg:选举算法,目前仅支持FastLeaderElection算法一种; server.id=[hostname]:port:port[:observer] 集群内各服务器的属性参数 第一个port:follower与leader进行通信和数据同步时所使用端口; 第二个port:leader选举时使用的端口; observer:定义指定的服务器为observer观察员; 每个服务器的id应该与数据目录下的相关关系保持一致
注意:运行为集群模式时,每个节点在其数据目录中应该有一个myid文件,其内容仅为当前server的id;
 新增节点
新增节点 把配置文件复制过去
把配置文件复制过去 另外新增的节点配置,两个都需要配置,mkdir创建数据目录
另外新增的节点配置,两个都需要配置,mkdir创建数据目录 下面需要修改配置文件
下面需要修改配置文件
 把配置文件复制过去
把配置文件复制过去
 定义的路径可能不太一样
定义的路径可能不太一样 创建目录,每个节点都需要创建,这个是主节点
创建目录,每个节点都需要创建,这个是主节点 把配置文件复制到其他节点上
把配置文件复制到其他节点上
 每个节点启动
每个节点启动 好像启动失败
好像启动失败
 好像都没什么问题 中间节点进行修改
好像都没什么问题 中间节点进行修改 试试standalon模式
试试standalon模式 就起来了
就起来了 启动不起来hi因为每个主机不能识别自己是谁,myid应该与serverid保持一致
启动不起来hi因为每个主机不能识别自己是谁,myid应该与serverid保持一致  2 节点标识为2
2 节点标识为2 
 现在启动就可以完成
现在启动就可以完成

 mode当前主机运行模式,follower
mode当前主机运行模式,follower  现在集群就启动起来了
现在集群就启动起来了

zookeeper的典型应用场景: 数据发布/订阅 负载均衡 命名服务 分布式协调/通知 集群管理 Master选举 只要部署HBASE不得不部署zookeeper, kafka严重依赖zookeeper 5台服务器,2台做observer,将来调整的无非就是java内存大小
转载地址:http://ujkgn.baihongyu.com/